Apache Kafka is a powerhouse for real-time data streaming, acting like a superhighway for data that never sleeps. For database engineers dipping their toes into streaming, it’s your bridge from batch processing to instant insights.
Kafka Basics
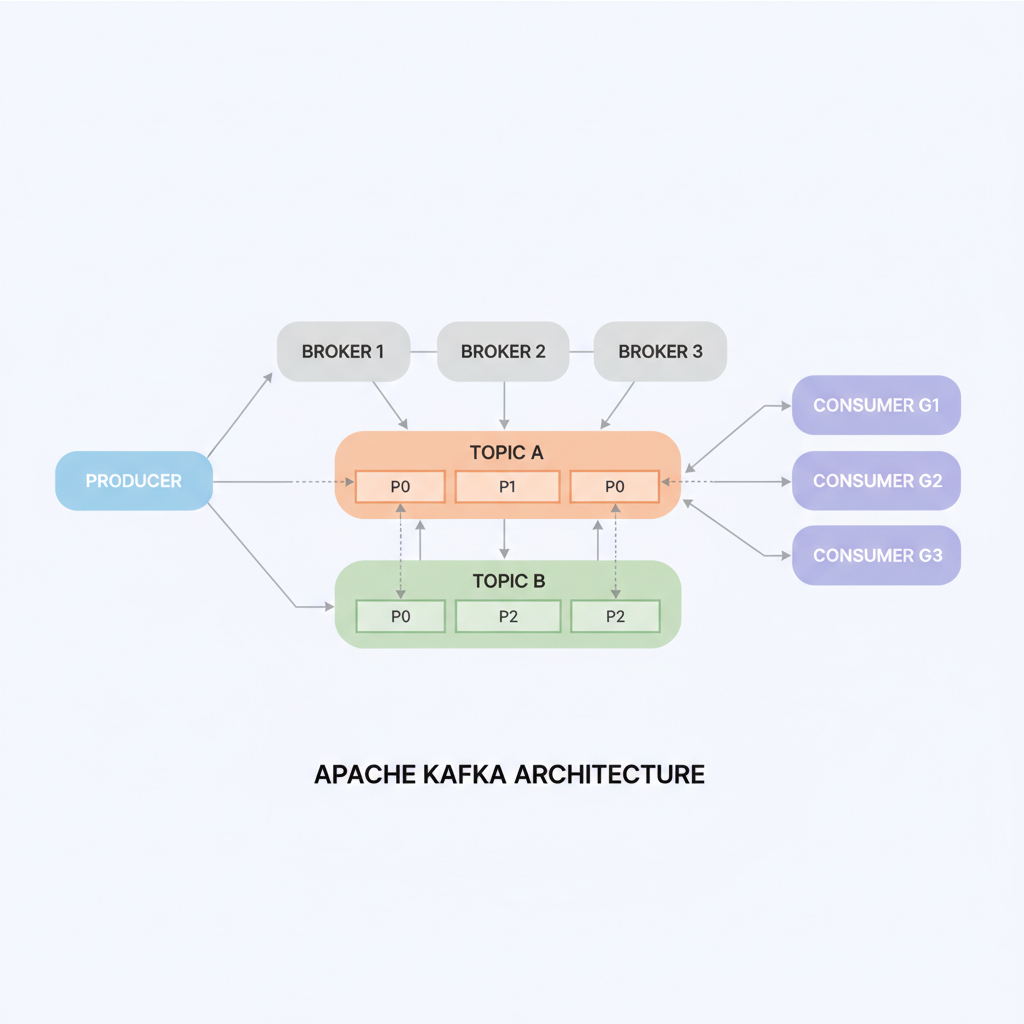
Picture Kafka as a distributed post office for massive data volumes. Producers (apps sending data) drop messages into topics—logical channels like mailboxes. These topics split into partitions across brokers (Kafka servers) for scalability and parallelism. Consumers subscribe to topics, pulling messages at their pace, with replication ensuring no data loss even if servers fail.
(see the generated image above)
This setup delivers high throughput (millions of messages/second), low latency, and fault tolerance—perfect for evolving from SQL queries to event streams.
Core Components
- Producers: Push data from sources like databases or sensors into Kafka topics.
- Brokers and Partitions: Brokers store data durably on disk; partitions enable horizontal scaling.
- Consumers: Read from topics independently, supporting multiple apps per stream.
- Connect and Streams: Kafka Connect links external systems (e.g., databases via CDC); Kafka Streams or Flink processes data in-flight for transformations.
As DBAs, think JDBC/CDC plugins feeding Kafka for real-time replication, sidestepping laggy ETL jobs.
Key Benefits
Kafka shines in durability (disk-backed logs for replays), pub-sub flexibility (one producer, many consumers), and seamless scaling.
(see the generated image above)
It integrates with your stack—PostgreSQL CDC to Kafka, then to Redshift or Elasticsearch—boosting monitoring like PMM/Grafana with live metrics.
Healthcare Wins
In healthcare, Kafka streams patient vitals from wearables for instant alerts, aggregates EHR logs for fraud detection, or pipes CDC from hospital databases to analytics for outbreak tracking—all HIPAA-compliant with encryption and audits. For DB engineers, it’s CDC gold: capture changes from MySQL/SQL Server in real-time, feeding ML models without downtime, unlike traditional replication.
Use Cases
- Real-time monitoring (e.g., ICU telemetry).
- Data integration (EHR to billing systems).
- CDC for compliant syncing.
- Event-driven apps (appointment reminders via microservices).
