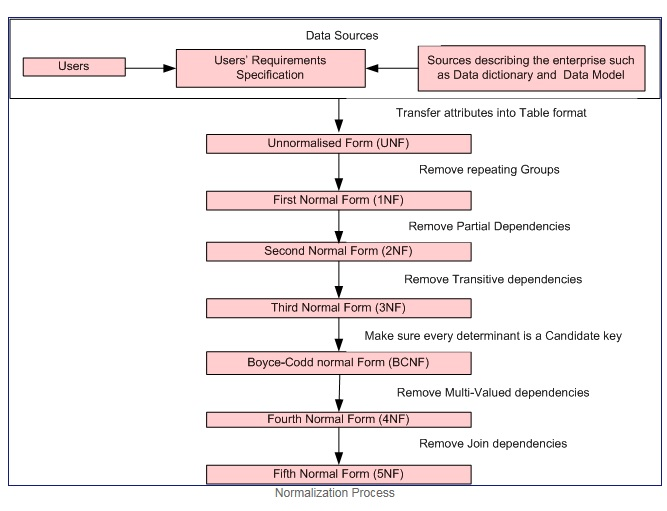
NORMALIZATION DIAGRAM
- ACID
- DDL, DML, and DCL
- PRIMARY/CANDIDATE KEYS
- TRIGGERS allowed
- DELETE TABLE vs TRUNCATE TABLE
- PRIMARY vs UNIQUE keys
- InnoDB Disk I/O
- NORMALIZATION
- NORMALIZTION II
ACID
Atomicity
Transactions are often composed of multiple statements. Atomicity guarantees that each transaction is treated as a single “unit”, which either succeeds completely, or fails completely: if any of the statements constituting a transaction fails to complete, the entire transaction fails and the database is left unchanged. An atomic system must guarantee atomicity in each and every situation, including power failures, errors and crashes.
Consistency
Consistency ensures that a transaction can only bring the database from one valid state to another, maintaining database invariants: any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof. This prevents database corruption by an illegal transaction, but does not guarantee that a transaction is correct. Referential integrity guarantees the primary key – foreign key relationship.
Isolation
Transactions are often executed concurrently (e.g., reading and writing to multiple tables at the same time). Isolation ensures that concurrent execution of transactions leaves the database in the same state that would have been obtained if the transactions were executed sequentially. Isolation is the main goal of concurrency control; depending on the method used, the effects of an incomplete transaction might not even be visible to other transactions.
Durability
Durability guarantees that once a transaction has been committed, it will remain committed even in the case of a system failure (e.g., power outage or crash). This usually means that completed transactions (or their effects) are recorded in non-volatile memory.
DDL, DML, and DCL
DDL is the abbreviation for Data Definition Language dealing with database schemas as well as the description of how data resides in the database. An example is CREATE TABLE command.
DML denotes Data Manipulation Language such as SELECT, INSERT etc.
DCL stands for Data Control Language and includes commands like GRANT, REVOKE etc.
PRIMARY/CANDIDATE KEYS
Primary key in MySQL is use to identify every row of a table in unique manner. For one table there is only one primary key. One of the candidate keys is the primary key and the candidate keys can be used to reference the foreign keys.
TRIGGERS allowed
AFTER INSERT
BEFORE UPDATE
AFTER UPDATE
BEFORE DELETE
AFTER DELETE
DELETE TABLE vs TRUNCATE TABLE
DELETE TABLE is logged operation and every row deleted is logged. Therefore the process is usually slow.
TRUNCATE TABLE also deletes rows in a table but it will not log any of the rows deleted. The process is faster in comparison. TRUNCATE TABLE can be rolled back and is functionally similar to the DELETE statement using no WHERE clause.
PRIMARY vs UNIQUE keys
While both are used to enforce uniqueness of the column defined but primary key would create a clustered index whereas unique key would create non-clustered index on the column. Primary key does not allow ‘NULL’ but unique key allows it.
InnoDB Disk I/O
InnoDB uses asynchronous disk I/O where possible, by creating a number of threads to handle I/O operations, while permitting other database operations to proceed while the I/O is still in progress. On Linux and Windows platforms, InnoDB uses the available OS and library functions to perform “native” asynchronous I/O. On other platforms, InnoDB still uses I/O threads, but the threads may actually wait for I/O requests to complete; this technique is known as “simulated” asynchronous I/O.
Read-Ahead
If InnoDB can determine there is a high probability that data might be needed soon, it performs read-ahead operations to bring that data into the buffer pool so that it is available in memory. Making a few large read requests for contiguous data can be more efficient than making several small, spread-out requests. There are two read-ahead heuristics in InnoDB:
In sequential read-ahead, if InnoDB notices that the access pattern to a segment in the tablespace is sequential, it posts in advance a batch of reads of database pages to the I/O system.
In random read-ahead, if InnoDB notices that some area in a tablespace seems to be in the process of being fully read into the buffer pool, it posts the remaining reads to the I/O system.
For information about configuring read-ahead heuristics, see Section 14.8.3.4, “Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)”.
Doublewrite Buffer
InnoDB uses a novel file flush technique involving a structure called the doublewrite buffer, which is enabled by default in most cases (innodb_doublewrite=ON). It adds safety to recovery following a crash or power outage, and improves performance on most varieties of Unix by reducing the need for fsync() operations.
Before writing pages to a data file, InnoDB first writes them to a contiguous tablespace area called the doublewrite buffer. Only after the write and the flush to the doublewrite buffer has completed does InnoDB write the pages to their proper positions in the data file. If there is an operating system, storage subsystem, or mysqld process crash in the middle of a page write (causing a torn page condition), InnoDB can later find a good copy of the page from the doublewrite buffer during recovery.
If system tablespace files (“ibdata files”) are located on Fusion-io devices that support atomic writes, doublewrite buffering is automatically disabled and Fusion-io atomic writes are used for all data files. Because the doublewrite buffer setting is global, doublewrite buffering is also disabled for data files residing on non-Fusion-io hardware. This feature is only supported on Fusion-io hardware and is only enabled for Fusion-io NVMFS on Linux. To take full advantage of this feature, an innodb_flush_method setting of O_DIRECT is recommended.
NORMALIZATION
In relational database design, we not only want to create a structure that stores all of the data, but we also want to do it in a way that minimize potential errors when we work with the data. The default language for accessing data from a relational database is SQL. In particular, SQL can be used to manipulate data in the following ways: insert new data, delete unwanted data, and update existing data. Similarly, in an un-normalized design, there are 3 problems that can occur when we work with the data:
- INSERT ANOMALY: This refers to the situation when it is impossible to insert certain types of data into the database.
- DELETE ANOMALY: The deletion of data leads to unintended loss of additional data, data that we had wished to preserve.
- UPDATE ANOMALY: This refers to the situation where updating the value of a column leads to database inconsistencies (i.e., different rows on the table have different values).
To address the 3 problems above, we go through the process of normalization. When we go through the normalization process, we increase the number of tables in the database, while decreasing the amount of data stored in each table. There are several different levels of database normalization:
- 1st Normal Form (1NF)
- 2nd Normal Form (2NF)
- 3rd Normal Form (3NF)
- Bryce-Codd Normal Form (BCNF)
- 4th Normal Form (4NF)
- 5th Normal Form (5NF)
The opposite of normalization is denormalization, where we want to combine multiple tables together into a larger table. Denormalization is most frequently associated with designing the fact table in a data warehouse.
NORMALIZTION II
Normalization in DBMS: 1NF, 2NF, 3NF and BCNF in Database
Normalization is a process of organizing the data in database to avoid data redundancy, insertion anomaly, update anomaly & deletion anomaly. Let’s discuss about anomalies first then we will discuss normal forms with examples.
Anomalies in DBMS
There are three types of anomalies that occur when the database is not normalized. These are – Insertion, update and deletion anomaly. Let’s take an example to understand this.
Example: Suppose a manufacturing company stores the employee details in a table named employee that has four attributes: emp_id for storing employee’s id, emp_name for storing employee’s name, emp_address for storing employee’s address and emp_dept for storing the department details in which the employee works. At some point of time the table looks like this:
emp_id emp_name emp_address emp_dept
101 Rick Delhi D001
101 Rick Delhi D002
123 Maggie Agra D890
166 Glenn Chennai D900
166 Glenn Chennai D004The above table is not normalized. We will see the problems that we face when a table is not normalized.
Update anomaly: In the above table we have two rows for employee Rick as he belongs to two departments of the company. If we want to update the address of Rick then we have to update the same in two rows or the data will become inconsistent. If somehow, the correct address gets updated in one department but not in other then as per the database, Rick would be having two different addresses, which is not correct and would lead to inconsistent data.
Insert anomaly: Suppose a new employee joins the company, who is under training and currently not assigned to any department then we would not be able to insert the data into the table if emp_dept field doesn’t allow nulls.
Delete anomaly: Suppose, if at a point of time the company closes the department D890 then deleting the rows that are having emp_dept as D890 would also delete the information of employee Maggie since she is assigned only to this department.
To overcome these anomalies we need to normalize the data. In the next section we will discuss about normalization.
Normalization
Here are the most commonly used normal forms:
- First normal form(1NF)
- Second normal form(2NF)
- Third normal form(3NF)
- Boyce & Codd normal form (BCNF)
First normal form (1NF)
As per the rule of first normal form, an attribute (column) of a table cannot hold multiple values. It should hold only atomic values.
Example: Suppose a company wants to store the names and contact details of its employees. It creates a table that looks like this:
emp_id emp_name emp_address emp_mobile
101 Herschel New Delhi 8912312390
102 Jon Kanpur 8812121212
9900012222
103 Ron Chennai 7778881212
104 Lester Bangalore 9990000123
8123450987
Two employees (Jon & Lester) are having two mobile numbers so the company stored them in the same field as you can see in the table above.
This table is not in 1NF as the rule says “each attribute of a table must have atomic (single) values”, the emp_mobile values for employees Jon & Lester violates that rule.
To make the table complies with 1NF we should have the data like this:
emp_id emp_name emp_address emp_mobile
101 Herschel New Delhi 8912312390
102 Jon Kanpur 8812121212
102 Jon Kanpur 9900012222
103 Ron Chennai 7778881212
104 Lester Bangalore 9990000123
104 Lester Bangalore 8123450987
Second normal form (2NF)
A table is said to be in 2NF if both the following conditions hold:
Table is in 1NF (First normal form)
No non-prime attribute is dependent on the proper subset of any candidate key of table.
An attribute that is not part of any candidate key is known as non-prime attribute.
Example: Suppose a school wants to store the data of teachers and the subjects they teach. They create a table that looks like this: Since a teacher can teach more than one subjects, the table can have multiple rows for a same teacher.
teacher_id subject teacher_age
111 Maths 38
111 Physics 38
222 Biology 38
333 Physics 40
333 Chemistry 40
Candidate Keys: {teacher_id, subject}
Non prime attribute: teacher_age
The table is in 1 NF because each attribute has atomic values. However, it is not in 2NF because non prime attribute teacher_age is dependent on teacher_id alone which is a proper subset of candidate key. This violates the rule for 2NF as the rule says “no non-prime attribute is dependent on the proper subset of any candidate key of the table”.
To make the table complies with 2NF we can break it in two tables like this:
teacher_details table:
teacher_id teacher_age
111 38
222 38
333 40
teacher_subject table:
teacher_id subject
111 Maths
111 Physics
222 Biology
333 Physics
333 Chemistry
Now the tables comply with Second normal form (2NF).
Third Normal form (3NF)
A table design is said to be in 3NF if both the following conditions hold:
Table must be in 2NF
Transitive functional dependency of non-prime attribute on any super key should be removed.
An attribute that is not part of any candidate key is known as non-prime attribute.
In other words 3NF can be explained like this: A table is in 3NF if it is in 2NF and for each functional dependency X-> Y at least one of the following conditions hold:
X is a super key of table
Y is a prime attribute of table
An attribute that is a part of one of the candidate keys is known as prime attribute.
Example: Suppose a company wants to store the complete address of each employee, they create a table named employee_details that looks like this:
emp_id emp_name emp_zip emp_state emp_city emp_district
1001 John 282005 UP Agra Dayal Bagh
1002 Ajeet 222008 TN Chennai M-City
1006 Lora 282007 TN Chennai Urrapakkam
1101 Lilly 292008 UK Pauri Bhagwan
1201 Steve 222999 MP Gwalior Ratan
Super keys: {emp_id}, {emp_id, emp_name}, {emp_id, emp_name, emp_zip}…so on
Candidate Keys: {emp_id}
Non-prime attributes: all attributes except emp_id are non-prime as they are not part of any candidate keys.
Here, emp_state, emp_city & emp_district dependent on emp_zip. And, emp_zip is dependent on emp_id that makes non-prime attributes (emp_state, emp_city & emp_district) transitively dependent on super key (emp_id). This violates the rule of 3NF.
To make this table complies with 3NF we have to break the table into two tables to remove the transitive dependency:
employee table:
emp_id emp_name emp_zip
1001 John 282005
1002 Ajeet 222008
1006 Lora 282007
1101 Lilly 292008
1201 Steve 222999
employee_zip table:
emp_zip emp_state emp_city emp_district
282005 UP Agra Dayal Bagh
222008 TN Chennai M-City
282007 TN Chennai Urrapakkam
292008 UK Pauri Bhagwan
222999 MP Gwalior Ratan
Boyce Codd normal form (BCNF)
It is an advance version of 3NF that’s why it is also referred as 3.5NF. BCNF is stricter than 3NF. A table complies with BCNF if it is in 3NF and for every functional dependency X->Y, X should be the super key of the table.
Example: Suppose there is a company wherein employees work in more than one department. They store the data like this:
emp_id emp_nationality emp_dept dept_type dept_no_of_emp
1001 Austrian Production and planning D001 200
1001 Austrian stores D001 250
1002 American design and technical support D134 100
1002 American Purchasing department D134 600
Functional dependencies in the table above:
emp_id -> emp_nationality
emp_dept -> {dept_type, dept_no_of_emp}
Candidate key: {emp_id, emp_dept}
The table is not in BCNF as neither emp_id nor emp_dept alone are keys.
To make the table comply with BCNF we can break the table in three tables like this:
emp_nationality table:
emp_id emp_nationality
1001 Austrian
1002 American
emp_dept table:
emp_dept dept_type dept_no_of_emp
Production and planning D001 200
stores D001 250
design and technical support D134 100
Purchasing department D134 600
emp_dept_mapping table:
emp_id emp_dept
1001 Production and planning
1001 stores
1002 design and technical support
1002 Purchasing department
Functional dependencies:
emp_id -> emp_nationality
emp_dept -> {dept_type, dept_no_of_emp}
Candidate keys:
For first table: emp_id
For second table: emp_dept
For third table: {emp_id, emp_dept}
This is now in BCNF as in both the functional dependencies left side part is a key.
